Deep-dive tutorials, guides, and articles on mathematics for engineers and developers

Machine learning is optimization. Calculus is the tool that tells you how to move your parameters to make the loss go down.
This article is a practical bridge between calculus and ML. We will focus on the ideas you actually use: limits, derivatives, gradients, the chain rule, and why gradient descent works.
No heavy jargon. Just clear explanations, small examples, and the intuition you need to debug real training code.
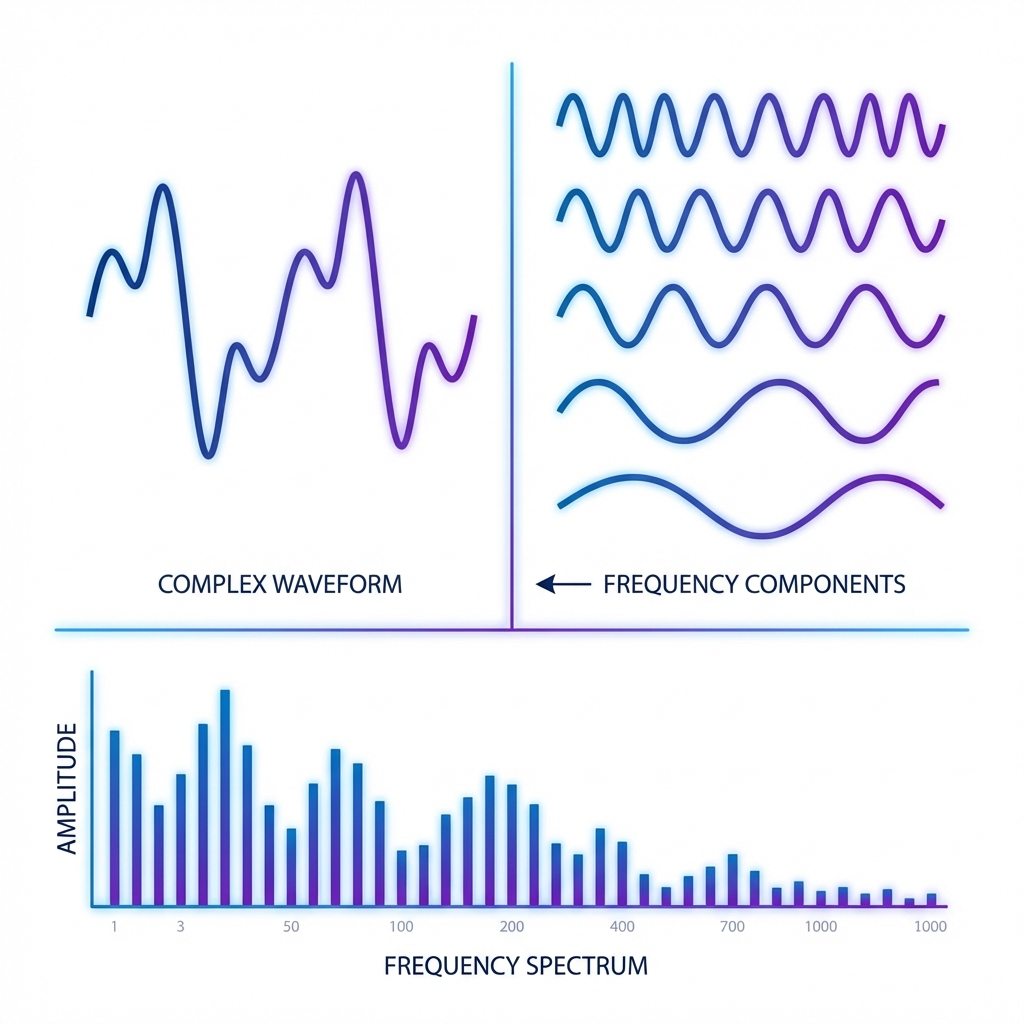
The Fourier Transform answers a simple question: what frequencies make up this signal?
If a waveform looks messy in the time domain, Fourier shows the clean building blocks underneath—sines and cosines. That is why it powers audio, images, compression, and many ML features.
This guide is practical and clear. We build intuition, show the formulas you actually use, and end with engineering tips like sampling and windowing.
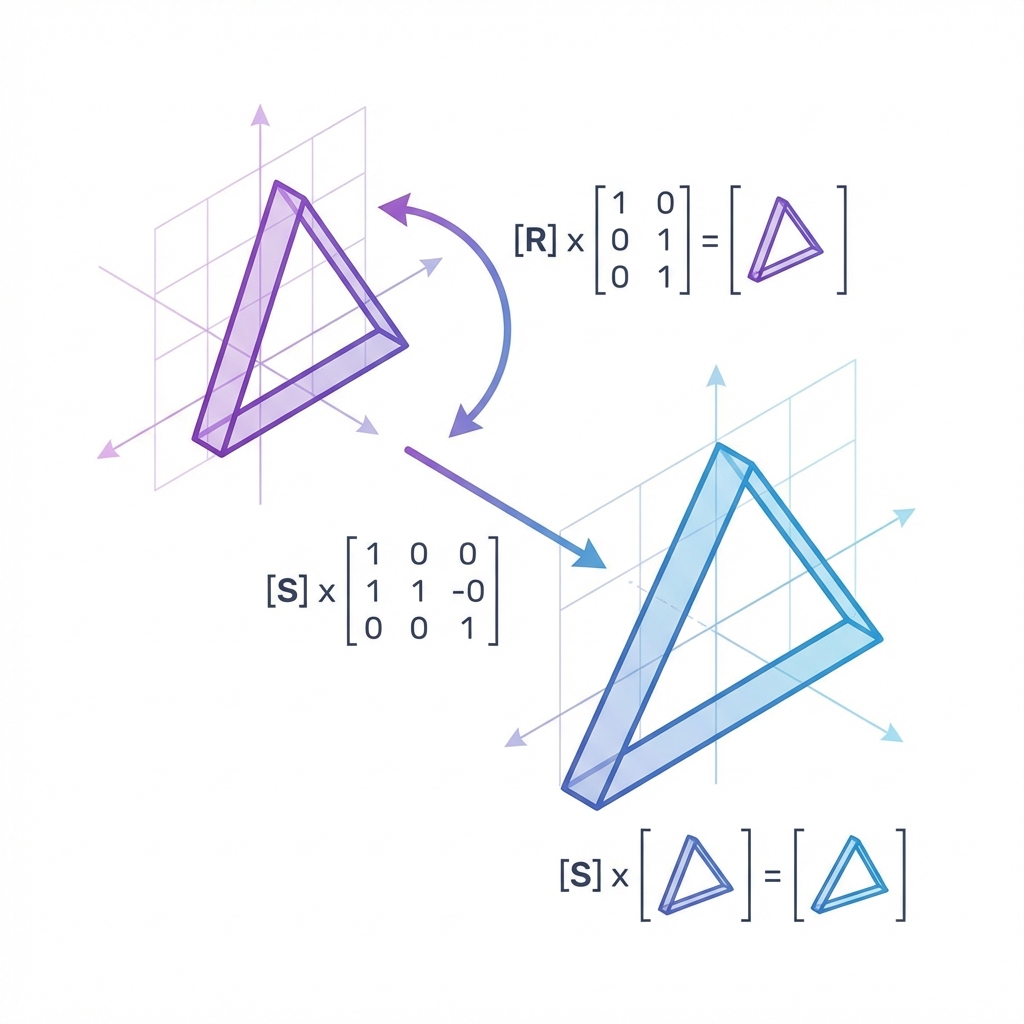
Computer graphics is linear algebra in motion. Every vertex, camera, and light is moved by vectors and matrices before a pixel is drawn.
This article is a practical guide. We will go from vectors and matrices to the full model‑view‑projection pipeline, explain why normals need special care, and show where most graphics bugs really come from.
You do not need to be a math major. You do need a clear mental model. That is what we will build here.

Quaternions are the workhorse of rotation in 3D games. They are compact, stable, and they blend smoothly without the gimbal‑lock problems of Euler angles.
This article is a practical guide. We will build intuition, show the exact formulas used in engine code, and focus on the common mistakes that make rotations look wrong.
If you can build a quaternion from axis–angle, multiply in the right order, and pick the right interpolation method, you already have 90% of what you need.
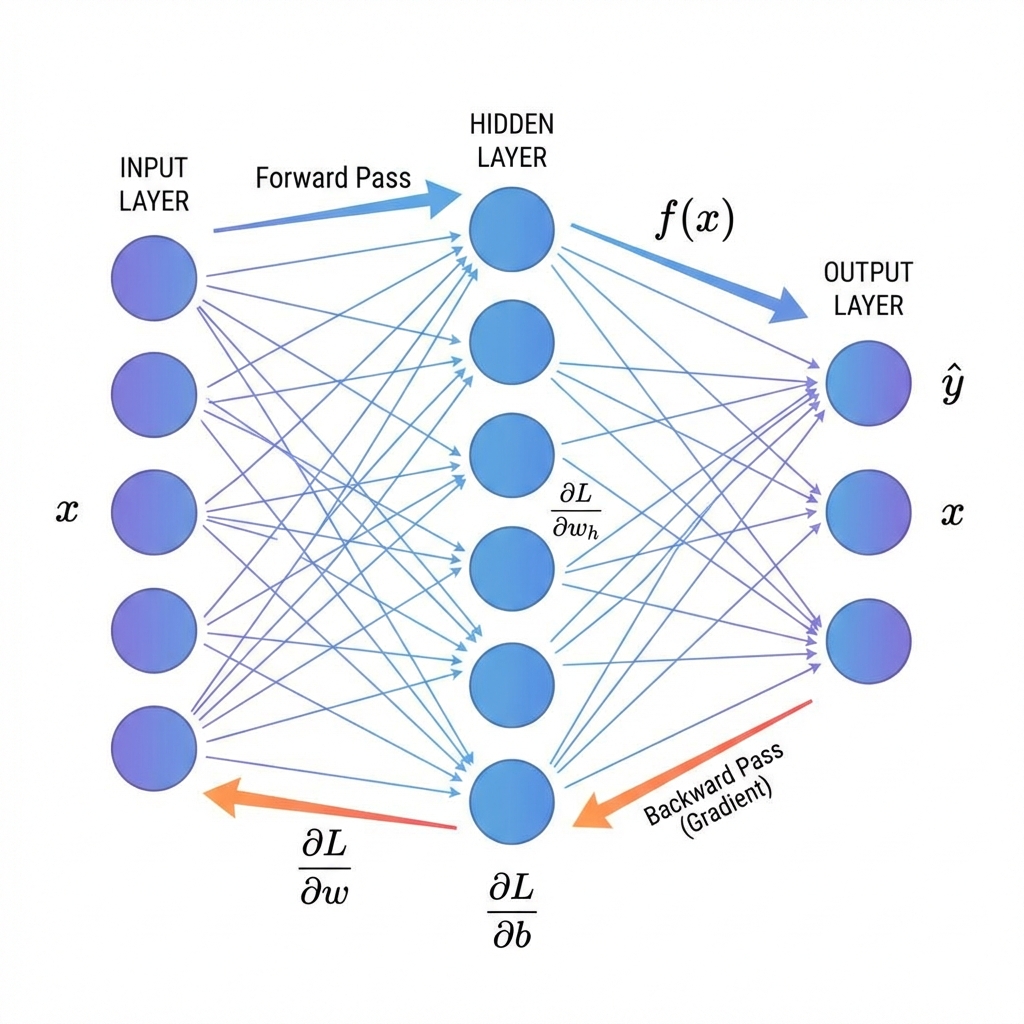
Backpropagation answers a practical question: if the prediction is wrong, which weights caused the mistake, and how much should each one change?
This guide builds the idea from the ground up. We start with one neuron, then a two-layer network, and finally the vectorized version used in real training. We keep the math honest, but we explain it in plain English.
If you can follow this article, you will be able to read gradient code, debug shape errors, and understand why modern frameworks compute gradients the way they do.
Start a 7‑day trial to unlock adaptive paths, streak momentum, and cross-domain mastery.
Founding member pricing available now.
Preview is free. Trial unlocks full adaptive sessions, labs, and mastery analytics.
